Model Overview

Data
Eligible Players
The model is trained on MLB and MiLB data going back to 2005, and college data going back to 2002. Any player who had played in MLB or MiLB before 2005 is excluded from the list of players, although players who don't have full college data are included due to (A) relatively few players missing data that aren't missing MiLB data and (B) difficulty in determining who these players are. In order to allow for players to have enough time to actually accumulate WAR if they are successful, players who signed after 2014 are not included in the training dataset, as well as players who were under 21 for the 2015 season, as a significant amount of the successful players in that cohort are still under MLB team control accruing value. In addition, any players who signed an MLB contract from a professional league (typically the NPB) are not included in training either, as the model does not have other league data.
For predictions on next-year statistics, players with data before 2005 are not eligible, but all other players are. No data after 2024 was used in training statistics, position, or playing time predictions. Stat predictions do not stop once a player has stopped being a prospect in the model.
Inputs (X)
For a player, a stats input is generated each month, as well as one upon player signing. When a player plays at multiple levels in a given year, the stats are combined, with the level being the weighted average of the levels for the month. All stats are normalized to the league at which the player is at, so rather than having a player's AVG, it instead has their AVG as a multiple of the average AVG at that league for that period. If a player has no stats for a month, empty stats will be added if their previous level played 20% or more of their max monthly games that month, otherwise no update is applied. This ends up resulting in some abnormalities around the 2020 season, where player in the low minors who played in 2019 have absolutely no input data until they are 2021, where they are suddenly over a year older. Any games played before April are merged into April, and any games played after September are merged into September.
The following stats (click to expand) are used to create pro inputs at each time step. BSR, OFF, DEF, WAR are custom stats for MiLB and obtained from Fangraphs for MLB
Both- Age at signing
- Draft Pick
- Draft Signing Rank
- Age
- Level
- Month
- PA
- League PA as % of largest month
- Player Injured Status
- Park Run Factor
- Park HR Factor
- 1B
- 2B
- 3B
- HR
- BB
- HBP
- K
- SB
- CS
- % of games started at each position
- BSR
- OFF
- DEF
- WAR
- ERA
- FIP
- wOBA
- HR%
- BB%
- K%
- Groundout%
- WAR
For players that first played in college, the player is run through a seperate college model, which has its results fed into the pro model when the player begins their pro career. Empty data is fed in for any gap years in eligiblity.
The following stats are used to create college inputs at each time step.
Both- Year of Eligibility
- Age
- Park Run Factor
- Average Conference RPI
- PA
- 1B
- 2B
- 3B
- HR
- BB
- HBP
- K
- SB
- CS
- IP
- ERA
- FIP
- WHIP
- H9
- HR9
- BB9
- K9
- GS
- G
Output (Y)
To evaluate each player, an attempt was made to determine their total output WAR through team control. This is not an easy point to determine exactly where it begins and ends for each player: options, waivers, Rule 5 Draft eligibility, how a player was aquired, and minor league free agency make it more complicated than just looking at the total WAR accululated until the player has enough service time to reach free agency. To determine the cutoff point, the following approach was used. The model will only cut off at the end of a season.
- If a player reaches their age 27 season without making their MLB debut, the model cuts off, resulting in 0 WAR
- If a player reaches the MLB and then does not play in MLB for 2 years, the model cuts off (the player was likely waived)
- If a player reaches age 34, the model cuts off (a player would not be under team control at this point)
- If a player reaches their free agency eligibility, the model cuts off
For statictics predictions, all of the input stats for a hitter/pitcher are predicted individually, with the exception of those that are derived from other predicted statictics (WAR, FIP) on a per-PA basis, and then scaled by the playing time prediction. For training, levels that do not meet 50PA/50BF are not considered for training to reduce noise. While input data is done on a per-month basis, output data is done on a rolling calendar year basis; a prediction after the model has been run on May data would be predicting the rest of the current year in addition to April and May of the next year.
Model
RNN
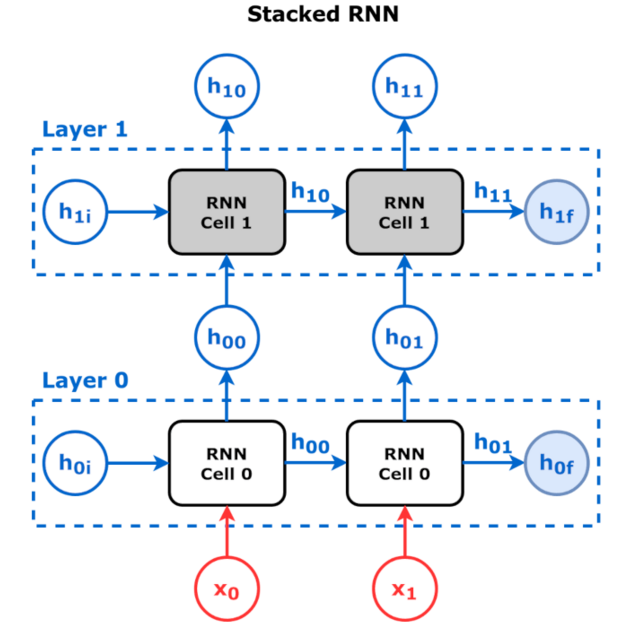
The main portion of the model lies in a Stacked RNN, label as RNN in the high level view. The RNN takes in two inputs, the input state and the previous hidden state, and returns an updated hidden state. This output is then fed into the next month of the model, as well as to the player state to make predictions with. A diagram of a stacked RNN in showed below.
Player Model and Output (Y)
The output of the RNN, the hidden statehx, is used to create the player state, and that state is used to create the outputs for the model. Once the model reaches the player state, it then diverges into predicting a number of different outputs. The player state then generates a number of pre-output states, which are then used to create a number of different outputs.
Once the model has reached the pre-output states, it is no longer a densely connected network with each node being influenced by each other node. For output M, outputs YM0 through YMN are generated only using pre-output states ZM0 through ZMN, and no influence from other pre-output blocks. This segregates each output into its own block, with this block translating the player state into a prediction that can be tested.

For the model outputs, they are done using classification using softmax to get the probability of each class. Doing classification for the predictions is done for two reasons. The first is that it allows for a probability distribution to be shown rather that just a number, so this model can differentiate between a player that is likely to be an MLB player but unlikely to be a star and a player who has a chance to be a star but is unlikely to make the show. The second is that the distribution of player outcomes is not normal: the range of Hitter WAR during control was -4.3 to 53.9. In training networks, using L2 loss (taking the error squared) generally gives better results than just the error, but in this case it would result in overvaluing players because a few superstars would generate a large model loss. Instead, WAR is put into a number of different buckets and the model generates a probability that the player ended up in each bucket.
The model currently generates a number of different outputs: WAR through control, peak seasonal WAR during control, the total PA/outs for a hitter/pitcher in MLB, and the highest level that a player achieved, their stats during the next calendar year at each level, their positions played in the next calendar year at each level, their OFF/DEF/BSR value during MLB control, and their playing time at each level. All of these are predicted during the same model run, allowing for the model to learn much more detailed information about why prospects are succeeding or failing. Somewhat surprisingly, predicting the player's level and the player's WAR generates a better WAR prediction than just predicting their WAR, and this being true for all of the predicted values and prospect WAR.
While the model makes good predictions for prospect value, the predictions about MLB stats do not seem to be up to par compared with other public models and team evaluations on players. The stat predictions tend to over-regress values towards the mean, meaning that players who are outliers on a statistic (such as Aaron Judge on HRs) tend to get underrated, while players who have clear flaws tend to get overrated as the model believes their weakness will significantly improve. That stat predictions do tend to agree with most players on their relative ranking, its values for top players is significantly lower than public models.